Abstract
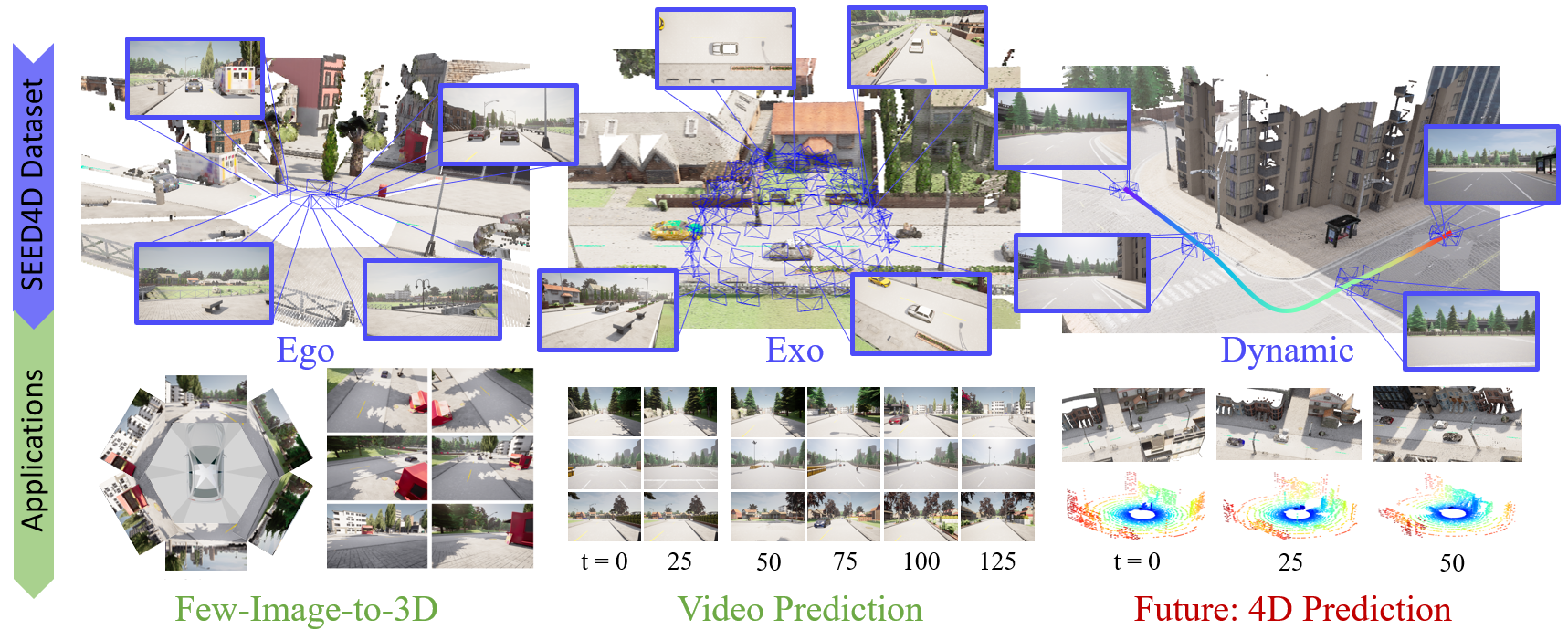
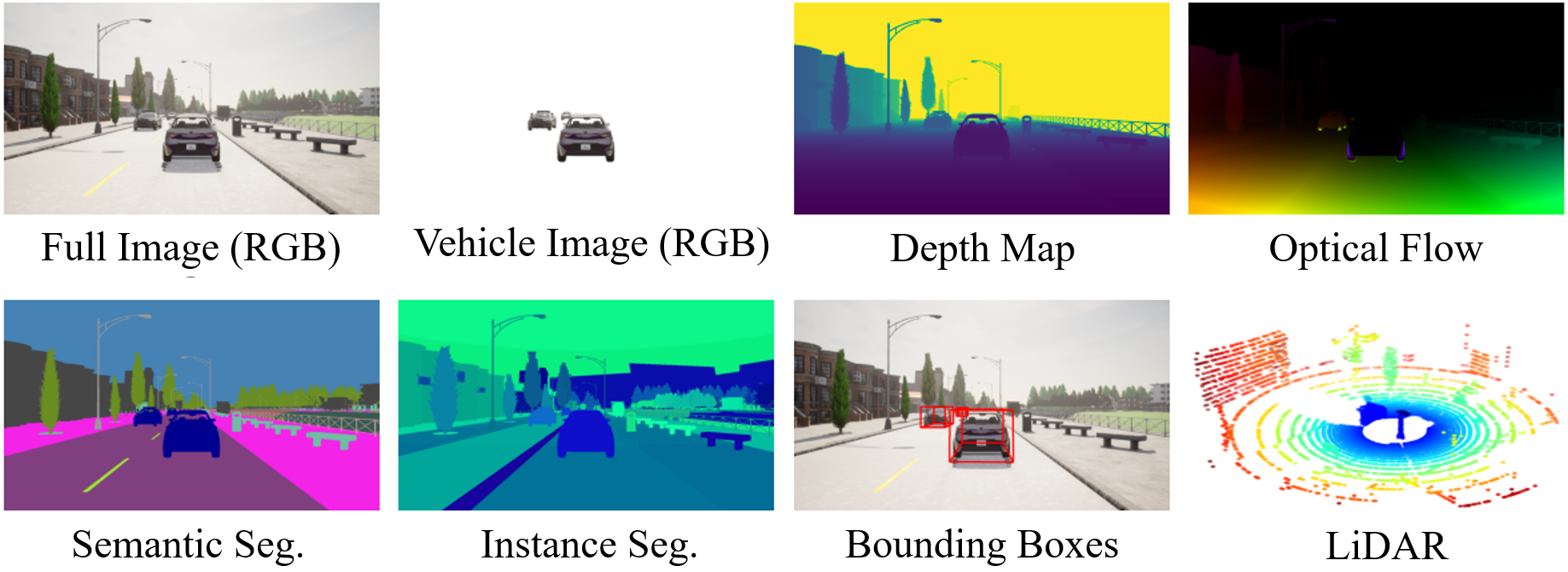
SEED4D is a large-scale synthetic multi-view dynamic 4D driving dataset, data generator and benchmarks. Models for egocentric 3D and 4D reconstruction, including few-shot interpolation and extrapolation settings, can benefit from having images from exocentric viewpoints as supervision signals. No existing dataset provides the necessary mixture of complex, dynamic, and multi-view data. To facilitate the development of 3D and 4D reconstruction methods in the autonomous driving context, we propose a Synthetic Ego--Exo Dynamic 4D (SEED4D) dataset. SEED4D encompasses two large-scale multi-view synthetic urban scene datasets. Our static (3D) dataset encompasses 212K inward- and outward-facing vehicle images from 2K scenes, while our dynamic (4D) dataset contains 16.8M images from 10K trajectories, each sampled at 100 points in time with egocentric images, exocentric images, and LiDAR data. We additionally present a customizable, easy-to-use data generator for spatio-temporal multi-view data creation. Our open-source data generator allows the creation of synthetic data for camera setups commonly used in the NuScenes, KITTI360, and Waymo datasets.


















































































{kind=link}